
Around May of 2022, I was tasked with ripping around 1,500 DVDs for upload to a new, on-premise, Video-On-Demand system. During this time I was working as a seasonal intern in the tech department for my high-school district. In previous years, my colleagues and I often found ourselves tediously configuring thousands of iPads for deployment the following school-year, so I was excited to head a project (mostly) on my own. While as an intern I wasn’t technically the head of the directive, the project manager gave me lots of leeway in how I wanted to execute the massive undertaking of ripping just over a thousand DVDs sent in from each school’s library and the deployment of the accompanying software to each classroom computer.
Software + hardware
For those familiar with Plex, Emby is a similar concept. DVDs and other media can be uploaded to a central server, and then that can be streamed over the network to clients across the district. Emby would pull metadata for each movie or TV show, provided that it could scrape the title and year of the content from the filenames so that it could hit TheMovieDB’s or TVDB’s API. Each of the 4 schools would have a server on-premises with a RAID array attached that would store all the content. In terms of what I was provided with to execute the project, I was given a naming convention for how movies and TV shows should be named, a rough guide on how to use the ripping software–MakeMKV, and a Google Sheet from each library of what was sent in. I also setup about 10 computers that I could remote into to manage the ripping process.

I very quickly realized that doing this by hand: clicking through each prompt in MakeMKV, sorting through resulting .mkv’s to see. what was duplicates, just scenes, or special features, was impractical. I needed a script. Turns out the project manager above me figured I would do something like that, he just didn’t think I would have one written and ready by Day 2 of the project.
Franktheripper2.ps1
In an ideal world, I wanted my Powershell script to eat a disc, rip it, and eject it. But, turns out, there’s a lot of exceptions to how movies and TV shows are distributed on physical media. Sometimes there’s special features, sometimes there’s not. Sometimes there are, but they’re on a second disc. Did we want special features? If so, all of them? Sometimes there’s two parts to a single movie. Were those spread across two discs? Would we edit them together? Sometimes discs were compilations of the Christmas episodes across a series. Did we want to upload those to a separate folder in the system to match the season/episode numbering, or keep them in them together as a “collection”, as Emby calls it?
Clearly, there were many exceptions and I knew I wouldn’t be able to handle all of them. Talking with my project manager, he honestly gave me a lot of independence in what I thought was the best way to handle these exceptions. And honestly, two years later, I don’t really remember how I handled them myself. (Good thing I wrote a 20 page guide on how to do this for the librarians, more on that later) However, I knew that with a basic enough structure, I could at least greatly reduce the manual effort required in organizing the rest of the files. So, I settled on it accomplishing a few things:
- Accept disc
- Rip up to a 2 disc movie: 1 movie disc, and 1 special feature disc
- It would finishing ripping the first one, then ask for the second before moving onto renaming
- Rename those files according to the convention
- Upload those files according to the directory structure convention to the correct building
- Eject disc
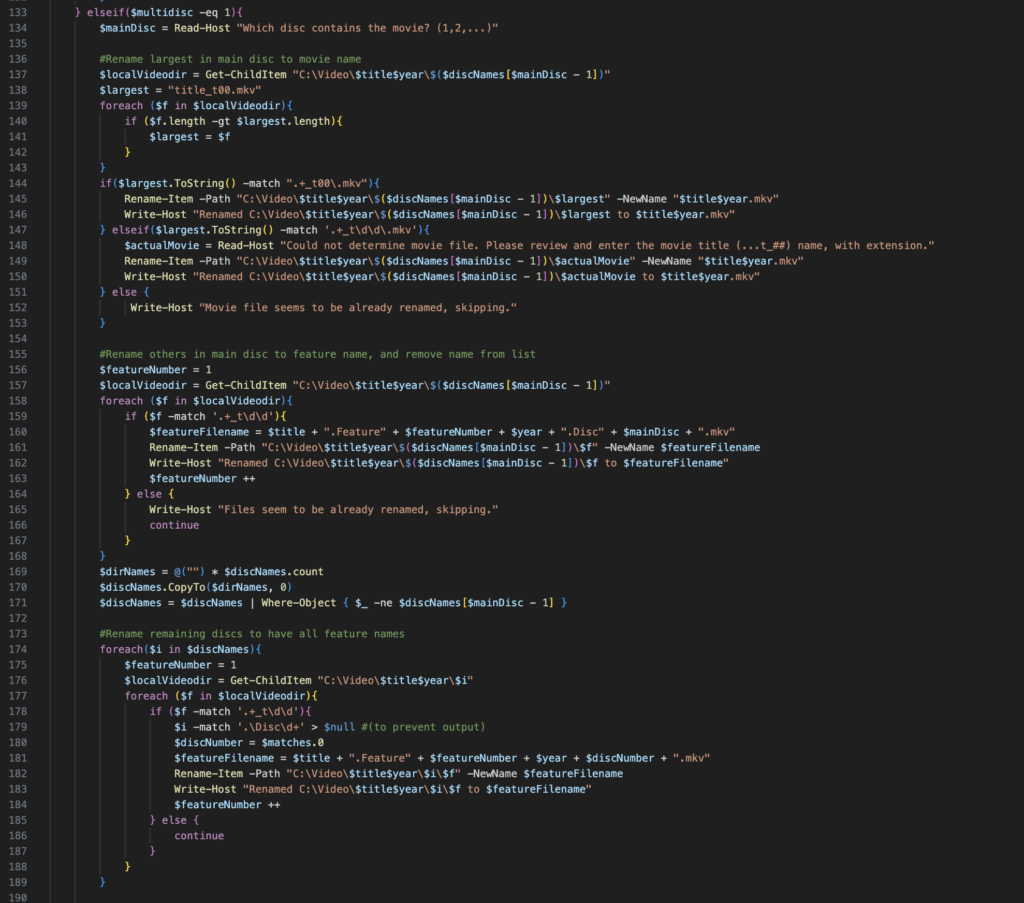
Keep in mind that after ripping a disc, the files weren’t nicely named based on what they were. They all came out as “title_t##.mkv”‘s, where the ## was just ascending from 00 to however many .mkv files there were. However, after that first day of doing them, I saw enough trends in how they were organized that I could make a few assumptions.
- If “title_t00.mkv” is the largest file, that’s the “movie” file and can be named as such
- If the largest file was a different “title_t##” file, ask for confirmation from user
- Another file that was exact same size was likely just a duplicate (not sure why that was a thing, but it was), but since this was the movie content, I wanted to be sure that it was being named and uploaded correctly
- If the largest file was a different “title_t##” file, ask for confirmation from user
- All files on the second disc were special features, and would be moved to the “extras” directory
- While this may not have been true for all, we had to have some sort of standard. The movie would be named according to the movie name and year, and the rest would just have “.Feature#” appended to it. Really what mattered was that we were catching all the content, not necessarily the detail in the naming of content as that wasn’t our priority (i.e. the movies/TV shows).
And it worked very well. All I had to do was insert a disc, answer some questions regarding the title and year of the movie, and based on the size of the resulting files it would determine what were the movie files and what were the feature files. I had coded the directory structure for each in, so when it uploaded them it would create the correct directories with the right names, and upload each file to each directory.
Client-side deployment
After all was said and done, all 1,500 or so DVDs had been uploaded into system. However, that was only half the battle. We still needed to get Emby on all of the classroom iMacs. Now, simply getting it on there wasn’t too much of an issue. The district had already set-up Munki and was using it for deployment of some applications already. However, Emby had one extra configuration we wanted to include: we wanted it to already be logged into the correct building (i.e. East computers would be logged into the East server). So, I settled on diving into the container files of the application to figure out what held the credentials for login.
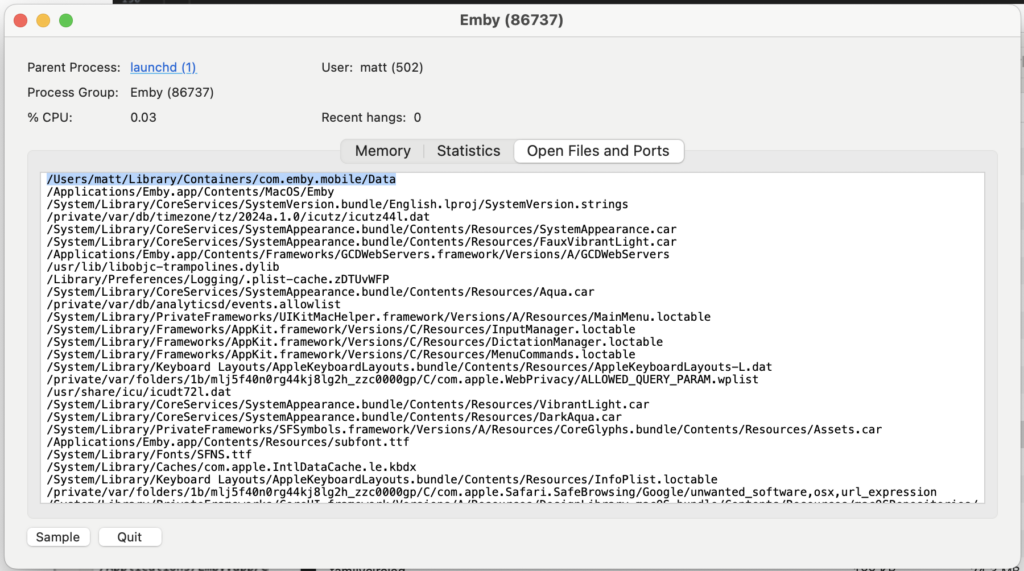
I had narrowed it down to the “com.emby.mobile” container. I recall there being an actual database for the credentials (I don’t have any screenshots from when I was actually doing all this unfortunately), but I don’t think transferring that over ended up working. So, I figured just using the entire container as the basis for each .pkg that I would be creating would be okay, since each was built on a fresh install of the application with district-wide credentials in App Store. Any crossover data between buildings wasn’t a huge concern.
And that was the next step, creating a .pkg file for distribution. For each building I built a .pkg file (using Munkipkg) that would place the Munki app in the Applications directory, and the container in the Containers directory. I uploaded those .pkg’s to the Munki repo and set conditions on each pkg to deploy based on hostname, as computers had a component of the hostname that was based on the building it was in.
Quality of Execution?
Eh? It went alright. Unfortunately, I wasn’t really able to test out the deployment on a set of pilot devices as I should have. I had like two MacBooks in the room with me that I would change their hostnames to simulate different buildings, and for my ridiculously small sample size of two, deployment went fantastic. I would run a request for managedsoftwareupdate to check for updates, the “North” computer only saw the pkg for North and the “East” computer only saw the package for East. Download those pkgs, run them, and it was installed and logged in just as I had designed it to.
However, in the real world, everything seemed to deploy fine, but some clients would be logged in to the correct building, and others just wouldn’t be logged in at all. It’s hard to tell what went wrong without actually looking at those client machines, but my assumption is I missed something about how Emby stored it’s credentials. Through all my testing, when I replaced that container with a different one, it would be logged into which ever container I gave it. I always made sure I cleared out everything related to Emby when I would change a computer’s hostname (to change the building), but it’s possible it was caching some aspect of the credentials elsewhere, thus making that container only a part of its login procedure.
In the end, the factor of it being deployed “logged in” wasn’t mission critical. It was simply a matter of resources. Updates had to be run on the computers anyway, so it really wasn’t much of an issue to ask the summer tech at that building that’s already hitting those computers to just log in to Emby as well.
Documentation
Documentation is one of the most important aspects of setting up a new system like this. With this system being a going concern that would have media uploaded to it as the libraries got more, I needed to document and set standards to how this massive system would be maintained. Really, it all came down to naming and organizational conventions. With the majority of the media being organized one way, breaking that convention once its all set-up could cause massive headaches down the line.
Enter the: Guide for Uploading and Maintaining the Emby Streaming System (Rev. 2022) (only now realizing the grammar there is a little questionable)
This 26 page document covered everything from naming the movies, to how to handle it when Emby doesn’t pull metadata correctly, to how to combine or split video files if need be, etc. This was the cherry on top of this whole project, and got printed and shipped out to each school with a PC for this to all be done on.
Conclusion
Overall, the project went very smoothly and even with the deployment hiccup, no major issues were encountered. Only one disaster where a RAID array crashed and they needed my script for to recover it, but other than that no issues. Is it still nice, neat and organized just as I left it, only with more media? Unfortunately, probably not. In fact, I don’t want to know what it looks like now. Probably many PBS Frontline episodes in the movies category. *shivers*